Paper „Deconstructing Deep Imbalanced Regression” in Artificial Intelligence Review erschienen
Paper „Deconstructing Deep Imbalanced Regression” in Artificial Intelligence Review erschienen
28. April 2026
Das Paper Deconstructing deep imbalance regression: a comprehensive review and experimental evaluation ist in Artificial Intelligence Review (Springer) erschienen: 10.1007/s10462-026-11570-1. Autoren sind Noah C. Puetz, Jens U. Brandt, Marc Hilbert, Elena Raponi, Thomas Bäck und Prof. Dr. Thomas Bartz-Beielstein. Die Arbeit entstand in einer Kooperation zwischen dem THK-AI Forschungscluster der TH Köln, dem LIACS der Universität Leiden und Toyota Racing in Köln.
Hintergrund
In vielen praxisrelevanten Regressionsproblemen sind genau jene Zielwerte besonders selten, die für Vorhersage und Risikobewertung am wichtigsten sind: Anomalien, Hochlastereignisse, Extremfälle. Während Deep Learning für solche Aufgaben eingesetzt wird, scheitern datengetriebene Modelle systematisch in unterrepräsentierten Bereichen des Zielraums. Dieses Phänomen wird in der Literatur unter dem Begriff Deep Imbalanced Regression (DIR) zusammengefasst und unterscheidet sich von der klassischen Imbalanced Classification durch die Kontinuität des Zielraums, die viele bewährte klassifikationsbasierte Gegenmaßnahmen unbrauchbar macht.
Fragestellung
Trotz wachsendem Interesse fehlten bislang zwei Bausteine: eine systematische konzeptionelle Einordnung der Methodenlandschaft und eine fair vergleichbare empirische Reevaluierung. Die Autoren stellen daher zwei Leitfragen: Lässt sich das DIR-Problem so strukturieren, dass Daten- und Modellseite getrennt analysierbar sind? Und welche der publizierten Verfahren halten unter identischen Trainings- und Evaluationsbedingungen tatsächlich, was sie versprechen?
Vorgehen
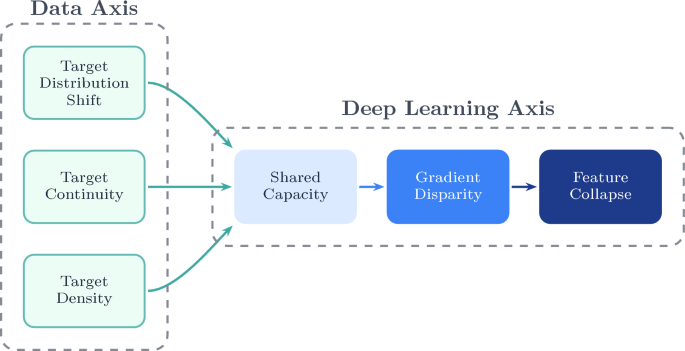
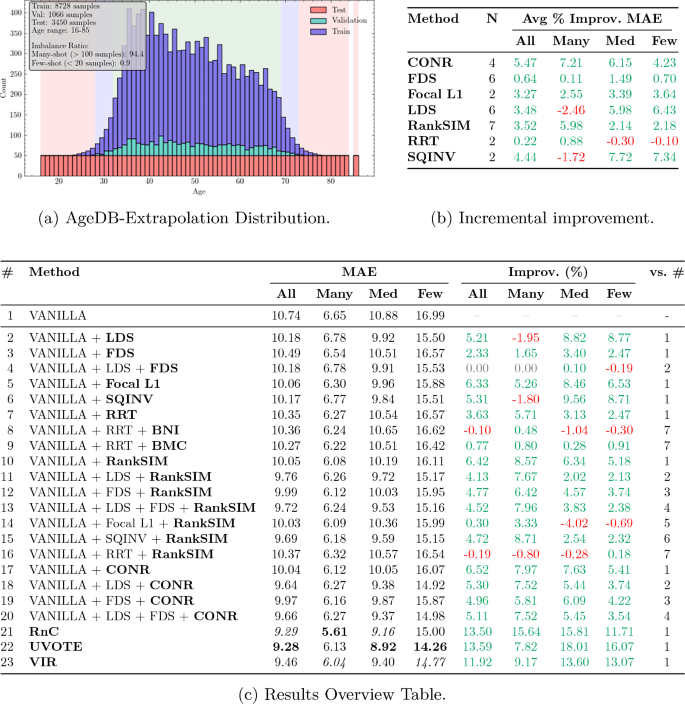
Im Zentrum der Arbeit steht eine zweiachsige Taxonomie. Die Data Axis fasst drei Eigenschaften des Zielraums zusammen, die in der Regression über bloße Klassenungleichverteilung hinausgehen: Verteilungsverschiebung zwischen Trainings- und Evaluationsverteilung, Kontinuität des Zielraums sowie lokale Dichte. Die Deep-Learning Axis beschreibt, wie diese Datenmerkmale im Inneren des Modells einen kaskadierenden Ausfall auslösen: geteilte Modellkapazität, die mehrheitlich von häufigen Bereichen vereinnahmt wird, führt zu Gradient Disparity zwischen häufigen und seltenen Regionen und mündet in Feature Collapse, bei dem seltene Zielwerte im Repräsentationsraum auf die Mehrheit kollabieren. Innerhalb dieses Rahmens werden 19 aktuelle Verfahren systematisch eingeordnet und zwölf davon mit verfügbaren Open-Source-Implementierungen unter identischer ResNet-50-Pipeline reevaluiert.
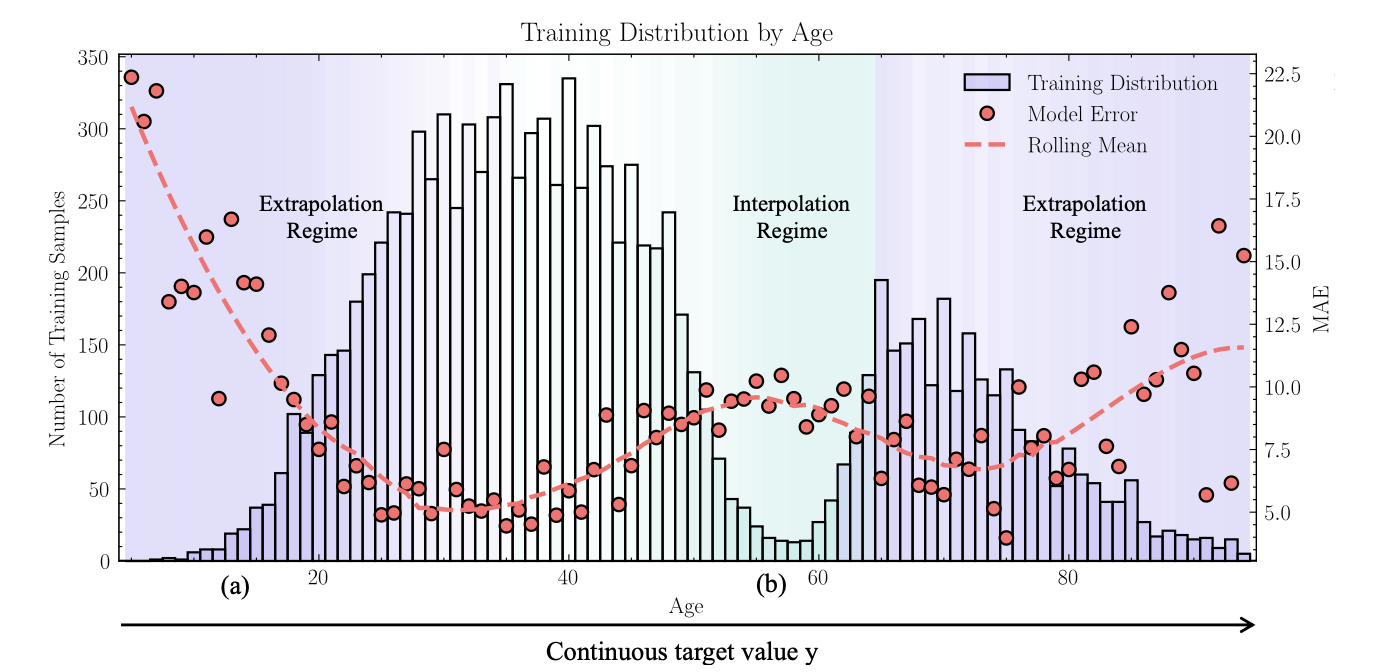
Damit die Bewertung über den Standard-Benchmark hinaus aussagekräftig bleibt, schlagen die Autoren drei neue Evaluationsprotokolle vor: Balanced Extrapolation (Test mit balanciertem Zielraum jenseits des Trainingsbereichs), Bimodal Interpolation (balancierter Test in einer Lücke zwischen zwei Trainingsmodi) und Blind-Spot Isolation (gezielte Auslassung eines zusammenhängenden Zielintervalls im Training). Diese Protokolle adressieren Schwächen, die im üblichen AgeDB-Benchmark verborgen bleiben.
Ergebnisse
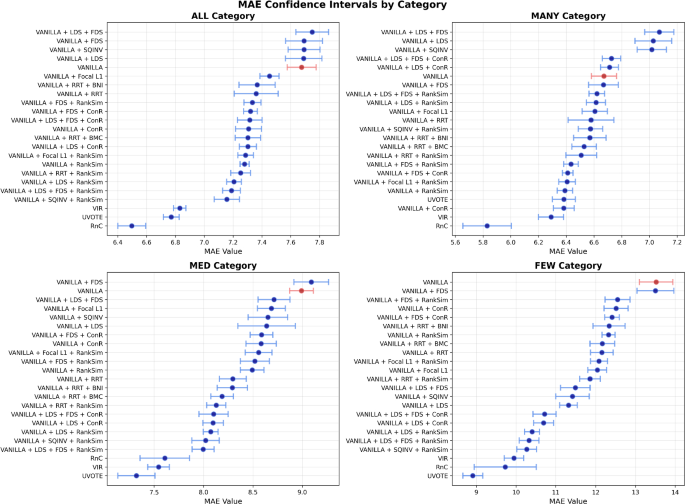
Die Reevaluierung zeigt, dass viele DIR-Verfahren auf dem Standard-Benchmark zwar messbare Verbesserungen liefern, ihr Vorsprung gegenüber einer einfachen Vanilla-Baseline jedoch unter den neuen Protokollen schrumpft oder ganz verschwindet. Insbesondere im Few-Shot-Bereich extrapolierter Zielwerte sowie in isolierten Blind-Spot-Regionen treten die durch die Kaskadenhypothese vorhergesagten Fehlermuster deutlich zutage. Eine begleitende Stabilitäts- und Laufzeitanalyse über elf Seeds und vier Datenregime ordnet die Verfahren zudem nach Vorhersagestabilität und Rechenkosten ein und macht praktische Trade-offs sichtbar.
In einem zusätzlichen kontrollierten Experiment auf dem UCI-Wine-Quality-Datensatz wird die Kaskadenhypothese erstmals gemeinsam für alle drei Stufen quantitativ vermessen: Wird der Engpass der geteilten Kapazität durch eine Multi-Head-Architektur entlastet, sinkt die Gradient Disparity messbar und der Feature Collapse wird abgeschwächt. Die Ergebnisse stützen die Lesart, dass DIR weniger ein Sammelbegriff für unverbundene Tricks ist als vielmehr ein gerichtetes Ausfallmuster, an dessen Anfangsstufe Interventionen besonders wirkungsvoll sind.
Quellcode, Protokolle und Auswertungsskripte sind unter github.com/noah-puetz/deconstructing_deep_imbalanced_regression verfügbar.
Förderung
Diese Arbeit wurde gefördert durch die Key Digital Technologies Joint Undertaking der Europäischen Kommission (HORIZON-KDT-JU-2023-2-RIA, Förderkennzeichen 101139996, Projekt ShapeFuture – Shaping the Future of EU Electronic Components and Systems for Automotive Applications) sowie durch das Bundesministerium für Bildung und Forschung (BMBF) im Programm Forschung an Fachhochschulen – KI-Nachwuchs@FH 2-2021 im Projekt TH Köln – Künstliche Intelligenz plus (THK-KIplus), Förderkennzeichen 13FH007KI2. Die geäußerten Ansichten sind ausschließlich diejenigen der Autoren und spiegeln nicht notwendigerweise die der Europäischen Union oder der Bewilligungsbehörde wider; weder die Europäische Union noch die Bewilligungsbehörde können dafür verantwortlich gemacht werden.
Zitation: Puetz, N. C., Brandt, J. U., Hilbert, M., Raponi, E., Bäck, T., Bartz-Beielstein, T. (2026). Deconstructing deep imbalance regression: a comprehensive review and experimental evaluation. Artificial Intelligence Review. https://doi.org/10.1007/s10462-026-11570-1.