Paper “LLMs taking shortcuts in test generation: A study with SAP HANA and LevelDB” published on arXiv
Paper “LLMs taking shortcuts in test generation: A study with SAP HANA and LevelDB” published on arXiv
2026-04-17
THK-AI Research Report 2/2026 has been published on arXiv: arXiv:2604.14437. The authors are Vekil Bekmyradov, Noah C. Pütz, and Prof. Dr. Thomas Bartz-Beielstein.
Background
Vekil Bekmyradov was a Master student at the THK-AI Research Cluster at TH Köln. His thesis was supervised by Prof. Dr. Thomas Bartz-Beielstein and Noah C. Pütz. The paper is a result of this supervision, which was done in cooperation with SAP.
Research question
Large Language Models achieve impressive results on public benchmarks, which is often read as evidence of advanced reasoning and understanding. Recent work in cognitive science, however, suggests that these models frequently rely on shallow heuristics and memorisation, taking shortcuts rather than demonstrating genuine cognitive abilities. The paper examines this pattern empirically in the domain of automated test generation for software.
Approach
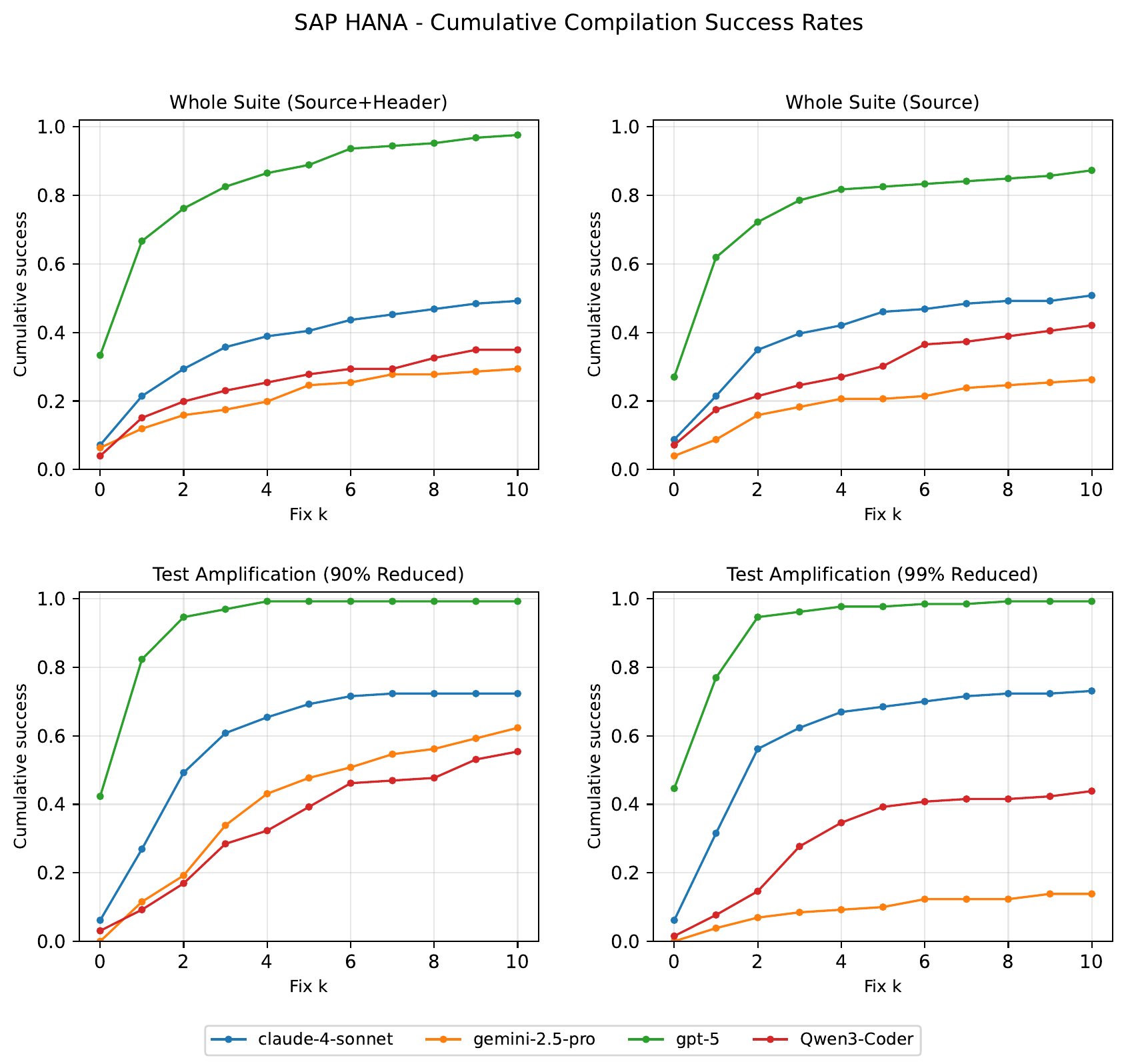
The study investigates LLM behaviour in test generation on two systems: the open-source LevelDB and the commercial database SAP HANA, one of the most widely deployed proprietary database systems worldwide. SAP HANA’s codebase is guaranteed to be absent from public training data, which lets the authors separate memorisation from genuine generalisation. Methodologically, cognitive evaluation principles following Mitchell’s mechanism-focused assessment are combined with empirical software testing, using mutation score and iterative compiler-feedback repair loops.
Findings
LLMs excel on familiar, open-source benchmarks but struggle with unseen, complex domains, often prioritising compilability over semantic effectiveness. The results provide independent software-engineering evidence for the broader claim that current LLMs lack robust reasoning, and argue for evaluation frameworks that penalise trivial shortcuts and reward true generalisation.
Citation: Bekmyradov, V., Pütz, N. C., Bartz-Beielstein, T. (2026). LLMs taking shortcuts in test generation: A study with SAP HANA and LevelDB. THK-AI Research Report 2/2026. arXiv:2604.14437.